
The 48 Hours That Changed AI Forever: Claude Opus 4.6’s Million-Token Agent Teams, GPT-5.3-Codex That Built Itself, and Gemini’s 750M User Explosion
Three Groundbreaking AI Announcements in Two Days—How Anthropic’s Agent Teams, OpenAI’s Self-Bootstrapping Model, and Google’s User Growth Just Redefined the Entire AI Landscape
Published: February 6, 2026 | Last Updated: 12:10 PM AEST | Reading Time: 16 minutes
February 4-5, 2026 will be remembered as the 48 hours that redefined artificial intelligence.
In a remarkable display of competitive innovation, three AI giants dropped game-changing announcements almost simultaneously:
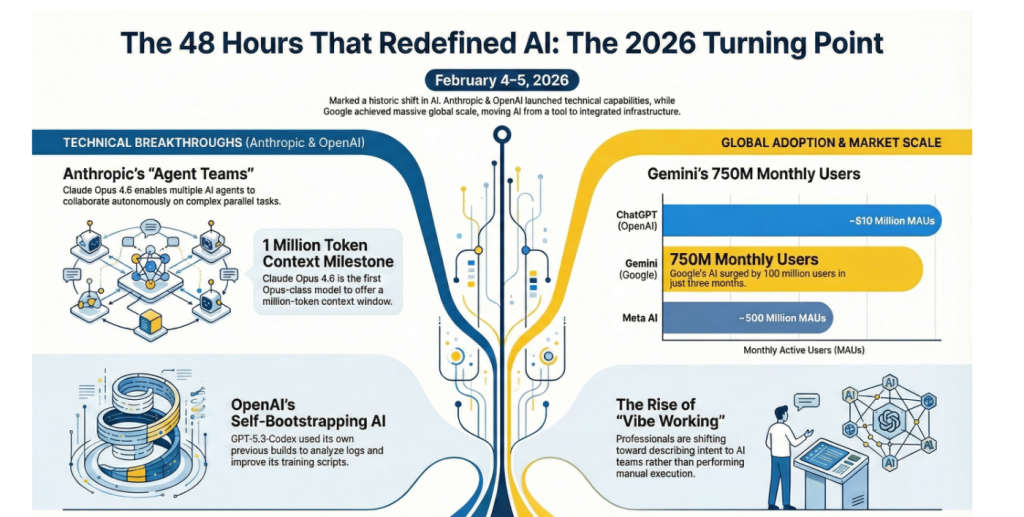
Anthropic launched Claude Opus 4.6 on February 5—the first Opus-class model with a 1 million token context window and revolutionary “agent teams” that collaborate autonomously on complex tasks without human intervention.
OpenAI countered hours later with GPT-5.3-Codex on February 4—the first AI model in history that literally helped build itself through “self-bootstrapping,” running 25% faster while combining frontier coding with GPT-5-class reasoning.
Google revealed in Q4 earnings that Gemini has surged to 750 million monthly active users—up 100 million in just three months—positioning it as the second-most-used AI chatbot globally, trailing only ChatGPT’s 810 million users.
This isn’t just news—it’s a fundamental shift in how AI models are developed, deployed, and adopted at scale. The question isn’t which company “won” the week, but what these simultaneous breakthroughs reveal about where AI is heading in 2026.
Claude Opus 4.6: The Agent Teams Revolution
What Makes Opus 4.6 Different
Anthropic’s latest flagship model represents a dramatic leap beyond traditional AI assistants. Released February 5, 2026, Claude Opus 4.6 introduces capabilities that blur the line between tool and autonomous workforce.
Core improvements over Opus 4.5:
- 1 million token context window (beta)—the first Opus-class model to reach this milestone
- Agent teams that work in parallel, coordinating autonomously
- Adaptive thinking where the model decides when deeper reasoning is needed
- Context compaction that automatically summarizes older context to extend task duration
- 128k output tokens for generating massive code files, documents, or analyses
- 25% faster execution on complex tasks compared to predecessor
But the real breakthrough isn’t just specs—it’s what the model can do with those capabilities.
Agent Teams: Multiple AIs Working as One
The most revolutionary feature in Claude Opus 4.6 is agent teams (available in Claude Code as a research preview). Here’s how it works:
You can now spin up multiple Claude agents that work in parallel as a coordinated team. Each agent tackles an independent subtask while the parent agent orchestrates the overall workflow.
Real-world example from Rakuten:
Claude Opus 4.6 autonomously closed 13 GitHub issues and assigned 12 issues to the right team members in a single day, managing a ~50-person organization across 6 repositories. It handled both product and organizational decisions while synthesizing context across multiple domains, and knew when to escalate to a human.
How agent teams work technically:
- Parent agent breaks complex task into independent, read-heavy subtasks
- Subagents spin up automatically and work in parallel
- Coordination happens autonomously—agents share context and dependencies
- Human oversight through Shift+Up/Down controls or tmux to take over any subagent
- Completion when all subagents report success or escalate blockers
This isn’t just parallelization—it’s genuine multi-agent collaboration where AIs coordinate strategy, divide labor, and integrate results without constant human guidance.
Benchmarks: Opus 4.6 Dominates Across Categories
Anthropic’s comprehensive evaluation shows Opus 4.6 leading or matching frontier models across nearly every benchmark:
Agentic Coding:
- Terminal-Bench 2.0: Highest score among all models
- SWE-bench Verified: 81.4% (with prompt modification, industry-leading)
- MCP Atlas: 62.7% (with max effort)
Knowledge Work:
- GDPval-AA: Outperforms GPT-5.2 by 144 Elo points (~70% win rate)
- BigLaw Bench: 90.2% (highest of any Claude model)
- BrowseComp: Best performance finding hard-to-locate information online
Long-Context Performance:
- MRCR v2 (8-needle, 1M variant): 76% vs Sonnet 4.5’s 18.5%—a 4x improvement in context retention
Reasoning & Expertise:
- Humanity’s Last Exam: Leads all frontier models on this complex multidisciplinary test
- OpenRCA root cause analysis: Superior diagnostic capability for software failures
- CyberGym: Enhanced cybersecurity assessment and vulnerability detection
Real-World Impact: What Early Access Partners Say
GitHub (Mario Rodriguez, Chief Product Officer):
“Early testing shows Claude Opus 4.6 delivering on the complex, multi-step coding work developers face every day—especially agentic workflows that demand planning and tool calling.”
Cognition/Devin (Scott Wu, CEO):
“Claude Opus 4.6 reasons through complex problems at a level we haven’t seen before. It considers edge cases that other models miss and consistently lands on more elegant, well-considered solutions.”
NBIM (Stian Kirkeberg, Head of AI & ML):
“Across 40 cybersecurity investigations, Claude Opus 4.6 produced the best results 38 of 40 times in a blind ranking against Claude 4.5 models.”
SentinelOne (Gregor Stewart, Chief AI Officer):
“Claude Opus 4.6 handled a multi-million-line codebase migration like a senior engineer. It planned up front, adapted its strategy as it learned, and finished in half the time.”
Pricing & Availability
Claude Opus 4.6 is available now across:
- Claude.ai web interface
- Claude API (use model name
claude-opus-4-6) - Claude Code (with agent teams in research preview)
- All major cloud platforms (AWS Bedrock, Google Vertex AI, Azure)
Pricing remains unchanged:
- Standard pricing: $5 input / $25 output per million tokens
- 1M context premium: $10 input / $37.50 output per million tokens (for prompts exceeding 200k tokens)
- US-only inference: 1.1× token pricing for data residency requirements
GPT-5.3-Codex: The AI That Built Itself
What “Self-Bootstrapping” Actually Means
Hours after Anthropic’s announcement, OpenAI launched GPT-5.3-Codex on February 4, 2026—and the headline feature sent shockwaves through the AI community: early versions of GPT-5.3-Codex helped build later versions of itself.
This isn’t science fiction. It’s a practical form of “AI-in-the-loop” development that OpenAI describes as transforming how their researchers and engineers work.
How GPT-5.3-Codex bootstrapped itself:
- Earlier internal builds analyzed training logs and flagged anomalies
- Identified failing tests and suggested fixes to training scripts
- Generated deployment configurations and infrastructure code
- Summarized evaluation regressions for human review
- Proposed changes to its own training process
OpenAI researchers describe their jobs today as “fundamentally different from what it was just two months ago.” The model essentially served as an on-call teammate across MLOps and DevOps tasks, compressing feedback cycles that typically consume expert time.
The Self-Improvement Implications
This isn’t unsupervised AI rewriting its own architecture. Humans remain in the loop with guardrails, version control, and offline evaluation. But the feedback cycle is faster and more automated.
Key capabilities enabling self-improvement:
- Reinforcement Learning from Human Feedback (RLHF): Codex uses human feedback on its outputs to refine behavior
- Fine-tuning on own outputs: Treats its own generated code as training data
- Self-debugging: Analyzes generated code for inconsistencies and optimization opportunities
- Automated diagnosis: Surfaces issues earlier and explores more hyperparameter space
The upside: Automated tooling can harden deployments, surface issues earlier, and accelerate research velocity dramatically.
The downside: “Bootstrap bias” where the model reinforces its own assumptions, and “specification gaming” where it optimizes for benchmark performance without improving real-world robustness.
This is where independent audits, red-team testing, and diverse benchmark suites become critical—a concern that researchers like Gary Marcus and academic labs have repeatedly highlighted.
Technical Improvements Over GPT-5.2-Codex
GPT-5.3-Codex isn’t just a faster version—it combines two previously separate models:
Architecture:
- GPT-5.2-Codex frontier coding performance
- GPT-5.2 reasoning and professional knowledge capabilities
- Unified in one model that’s also 25% faster
Key upgrades:
- Better collaboration during agent execution—more frequent progress updates
- Real-time steering responds to human guidance mid-execution
- Reduced non-deterministic loops that previously touched files repeatedly without progress
- Improved bug analysis with concrete supporting evidence
- Lower premature completion on flaky-test scenarios
Performance benchmarks:
While Anthropic didn’t release head-to-head Terminal-Bench comparisons, independent testing shows:
- GPT-5.3-Codex maintains strong SWE-bench Verified performance (80%+ range)
- Excels on SWE-bench Pro harder variant (56.4%)—stronger than previous Opus 4.5
- Approximately 30-40% faster implementation speed in real-world tasks
- Lower token usage due to more concise code generation
Availability & Access
GPT-5.3-Codex is available now:
- ChatGPT app (all paid plans: Plus, Team, Enterprise)
- Codex CLI command-line interface
- IDE extensions (VS Code, Cursor, Windsurf, etc.)
- Codex web interface
- API access coming soon
Infrastructure improvements:
OpenAI simultaneously deployed infrastructure upgrades that make GPT-5.3-Codex run 25% faster for all Codex users, resulting in faster interactions and shorter wait times for results.
Head-to-Head: Claude Opus 4.6 vs GPT-5.3-Codex
Two Philosophies of AI Advancement
These releases represent fundamentally different visions for AI’s future:
Agent Teams (Anthropic): Scales productivity horizontally—more agents equals more parallel work. Best for tasks that split into independent, read-heavy subtasks.
Self-Bootstrapping (OpenAI): Accelerates capability vertically—AI improves itself in recursive loops. Best for tasks requiring coherent, long-running execution.
Benchmark Comparison
| Benchmark | Claude Opus 4.6 | GPT-5.3-Codex | Winner |
|---|---|---|---|
| Terminal-Bench 2.0 | Highest score | Strong performance | Opus 4.6 |
| SWE-bench Verified | 81.4% (modified prompt) | ~80% | Tie (within margin) |
| SWE-bench Pro | Not disclosed | 56.4% | Codex (disclosed) |
| GDPval-AA (finance/legal) | +144 Elo over GPT-5.2 | Not tested | Opus 4.6 |
| Long-context (MRCR v2) | 76% | Not disclosed | Opus 4.6 |
| Implementation speed | ~8 min avg | ~7.5 min avg | Codex (30-40% faster) |
| Token efficiency | Verbose | Concise | Codex |
| Context window | 1M tokens | Not disclosed | Opus 4.6 |
| Output tokens | 128k | Not disclosed | Opus 4.6 |
Real-World Developer Experience
Reddit user comparisons (r/ClaudeCode, r/singularity):
Opus 4.6 strengths:
- Clean, readable, maintainable code structure
- Thorough edge case consideration
- Comprehensive test coverage
- Excellent architectural decision-making
- Better at defensive coding (input validation, error handling)
GPT-5.3-Codex strengths:
- Faster implementation (30-40% quicker on average)
- More concise code without excessive verbosity
- Stronger logical reasoning for algorithmic problems
- Better integration testing—code that integrates cleanly with existing APIs
- Fewer interruptions (doesn’t require constant approval)
Specific Test: Task Description Feature with Caching
Opus 4.6: Implementation time 8 min, partially working (UI stable when AI unavailable but cache incomplete), excellent code quality
GPT-5.3-Codex: Implementation time 7.5 min, failed to run (API version conflicts, unexported references), concise but integration issues
Winner: Opus 4.6—despite incomplete cache, the code compiled and partially worked. Codex’s version wouldn’t run at all.
When to Choose Each Model
Choose Claude Opus 4.6 for:
- Complex multi-agent workflows requiring parallel execution
- Tasks benefiting from 1M token context (large codebases, long documents)
- High-stakes applications where defensive coding reduces production bugs
- Financial, legal, and regulated industry work (GDPval-AA dominance)
- Long-running sessions where context retention matters
Choose GPT-5.3-Codex for:
- Fast iteration cycles where speed matters more than completeness
- Algorithmic problem-solving requiring logical reasoning
- Integration-heavy tasks connecting multiple APIs/services
- Workflows where concise output reduces token costs
- Projects where proven self-improvement feedback loops provide confidence
Google Gemini: The Silent Giant Hits 750M Users
The Growth Story Everyone Missed
While developers debated Claude vs Codex, Google quietly revealed the most stunning adoption metric of the week: Gemini has reached 750 million monthly active users as of Q4 2025, up from 650 million in Q3.
That’s 100 million new users in just three months.
How Gemini Stacks Up
Current AI chatbot rankings (MAUs):
- ChatGPT: ~810 million (estimated, late 2025)
- Gemini: 750 million (confirmed, Q4 2025)
- Meta AI: ~500 million (reported Q3 2025)
Gemini is now firmly the #2 AI chatbot globally, and it’s growing faster than ChatGPT, which saw user growth slow in late 2025.
What’s Driving Gemini’s Explosive Growth
1. Gemini 3 Launch (Q4 2025)
Google’s most advanced model showcased unprecedented depth and nuance in responses. CEO Sundar Pichai called Gemini 3 in “AI mode” a “positive driver” for growth.
2. Google AI Plus Plan ($7.99/month)
Launched January 27, 2026—more affordable than ChatGPT Plus ($20/month). While too recent to impact Q4 numbers, this positions Gemini for continued growth in 2026.
3. Tight Google Ecosystem Integration
Gemini is deeply embedded in:
- Google Search (over 10 billion tokens per minute processed via direct API)
- Android devices (default AI assistant on 3+ billion devices)
- Google Workspace (Docs, Sheets, Gmail integration)
- YouTube, Maps, Chrome (contextual AI features)
This distribution advantage is massive. While ChatGPT and Claude require users to visit separate websites or install apps, Gemini is already where billions of people work and browse.
4. Developer Adoption
Google announced that first-party models like Gemini now process over 10 billion tokens per minute via direct API use—indicating strong enterprise and developer uptake beyond just consumer chatbot usage.
The User Count Reality Check
Not all “monthly active users” are equal. Key questions:
How is “active” defined?
- ChatGPT: Users who send at least one message per month
- Gemini: Likely includes anyone who triggers Gemini in Search, Android, or Workspace—a much broader definition
- Meta AI: Includes passive interactions within Facebook/Instagram/WhatsApp
Engagement depth varies widely:
- Some “users” send one query and never return
- Others have hour-long coding sessions daily
- Gemini’s integration means many may not even realize they’re using it
Despite definitional differences, 750M users represents genuine scale. Even if only 10% are “power users,” that’s 75 million people actively engaging with Gemini for substantive work.
What This Means for the AI Race
Google’s Q4 earnings also showed Alphabet surpassing $400 billion in annual revenue for the first time—attributed partly to AI expansion. The company is investing heavily:
- Ironwood TPU chips to compete with Nvidia
- Gemini API infrastructure handling 10 billion tokens/minute
- Affordable tier expansion with AI Plus plan
Sundar Pichai’s statement in the earnings release: “Search saw more usage than ever before, with AI continuing to drive an expansionary moment.”
Google isn’t just competing in AI—it’s using AI to strengthen its core Search monopoly, creating a defensive moat against ChatGPT’s encroachment.
The Three Paradigms Reshaping AI in 2026
1. From Single Agents to Agent Ecosystems (Anthropic)
Claude Opus 4.6’s agent teams signal a shift from monolithic AI to collaborative multi-agent systems that mirror how human teams work.
Why this matters:
- Scalability: Complex tasks can be decomposed and executed in parallel
- Specialization: Different agents can optimize for different subtasks
- Resilience: If one agent fails, others continue; system degrades gracefully
- Transparency: Human can monitor and control individual subagents
Industries this unlocks:
- Software engineering: Code review, testing, documentation in parallel
- Financial analysis: Data gathering, modeling, compliance checks simultaneously
- Healthcare: Diagnosis, treatment planning, insurance coordination as team workflow
- Legal: Document review, case research, brief drafting by specialist agents
The risk: Coordination failures where agents work at cross-purposes, or emergent behaviors that weren’t anticipated in the design.
2. Self-Improving AI Systems (OpenAI)
GPT-5.3-Codex’s self-bootstrapping demonstrates that AI can accelerate its own development—a feedback loop that could exponentially increase capability gains.
Why this matters:
- Research velocity: Months-long research projects compressed into weeks
- Automated diagnosis: Models surface their own failure modes
- Continuous improvement: Each version trains the next more efficiently
Industries this unlocks:
- Pharmaceutical R&D: Models suggest experimental designs, analyze results, propose next experiments
- Materials science: AI explores chemical space, identifies promising compounds, designs synthesis pathways
- Chip design: Models optimize architectures, simulate performance, generate verification tests
The risk: Bootstrap bias, specification gaming, and the potential for misaligned objectives to reinforce through recursive self-improvement without human catch.
3. AI as Infrastructure, Not Product (Google)
Gemini’s 750M users reflect a strategy of embedding AI everywhere rather than building standalone chatbot products.
Why this matters:
- Reduced friction: Users don’t need to learn new interfaces or switch contexts
- Network effects: More usage generates more training data, improving models
- Defensibility: Integrated AI strengthens core products (Search, Android, Workspace)
Industries this transforms:
- Search & information retrieval: AI-generated summaries replace link lists
- Productivity software: AI becomes default co-author in docs, sheets, slides
- Consumer devices: AI assistants that genuinely understand device context and user history
The risk: Monopoly entrenchment where AI integration locks users into ecosystems, reducing competition and innovation.
The Implications: What This Week Means for 2026 and Beyond
For Developers: The Coding Landscape Just Shifted
Before this week:
- AI coding assistants accelerated individual productivity
- Developers still architected solutions, wrote tests, reviewed code
- AI was a tool, not a teammate
After this week:
- Multi-agent teams can handle end-to-end features with minimal guidance
- AI can propose improvements to its own training and deployment
- The line between “AI-assisted” and “AI-led” development is blurring
Action items for developers:
- Learn agent orchestration: Understanding how to coordinate multiple AI agents is becoming as important as coding itself
- Develop AI oversight skills: Your job shifts from writing code to reviewing AI-generated code and catching edge cases
- Master prompt engineering at scale: Effective delegation to AI teams requires clear specification and context management
- Build AI-native architectures: Design systems that can be introspected, modified, and extended by AI
For Enterprises: The Build-vs-Buy Calculation Changed
Claude Opus 4.6 and GPT-5.3-Codex reduce the cost of custom software by 10-100x compared to traditional development.
What this means:
- More companies will build: Projects that were cost-prohibitive are now feasible
- Faster experimentation: Proof-of-concepts take days instead of months
- Lower maintenance burden: AI can refactor and update codebases automatically
But new risks emerge:
- Technical debt at AI speed: Systems built quickly without human oversight accumulate hidden flaws
- Dependency on AI vendors: Lock-in to Anthropic or OpenAI ecosystems
- Regulatory uncertainty: Who is liable when AI-generated code causes harm?
Action items for enterprises:
- Pilot agent-based workflows: Start with low-risk internal tools before mission-critical systems
- Implement AI governance: Establish review processes for AI-generated deliverables
- Invest in AI literacy: Ensure teams understand AI capabilities and limitations
- Budget for AI infrastructure: Context-heavy agent teams require substantial compute
For AI Companies: The Arms Race Accelerates
This week proved that frontier AI development is now measured in days and weeks, not quarters.
Anthropic and OpenAI released major models within 24 hours of each other. Google announced massive user growth. The pace is intensifying.
What drives this acceleration:
- AI building AI: Self-improving systems compress research timelines
- Competitive pressure: No company can pause while rivals innovate
- Capital availability: Tens of billions in funding fuel simultaneous R&D efforts
- Talent density: Top researchers cluster at a few companies, enabling rapid breakthroughs
What this means for the market:
- Consolidation pressure: Smaller AI companies struggle to keep pace
- Vertical integration: Companies build entire stacks from chips to applications
- Open-source acceleration: Open models (DeepSeek, Llama, Mistral) must innovate even faster to stay relevant
The strategic question: Can anyone outside the Big 3-5 (OpenAI, Anthropic, Google, Meta, maybe xAI/Microsoft) compete long-term?
Looking Ahead: Five Predictions for AI in 2026
1. Agent Teams Become Standard by Q4 2026
Within 12 months, expect:
- Microsoft Copilot to add multi-agent orchestration
- GitHub Copilot Workspace to run agent teams on repositories
- Google Workspace to coordinate specialist Gemini agents across Docs, Sheets, Slides
- Enterprise AI platforms to offer agent team frameworks as core features
The shift from single AI assistants to coordinated teams will accelerate dramatically.
2. AI-Generated Code Passes 50% of New Code Commits
Currently estimated at 20-30% of code commits involving AI assistance. With Opus 4.6 and GPT-5.3-Codex capabilities, that could exceed 50% by year-end.
Implications:
- Code review processes must adapt to high-volume AI output
- Testing and validation become more critical than initial implementation
- “Software engineer” role shifts toward “AI orchestrator” and “system architect”
3. Self-Improving AI Triggers Regulatory Scrutiny
OpenAI’s self-bootstrapping announcement will draw attention from:
- EU AI Act regulators assessing “high-risk” systems
- U.S. AI Safety Institute examining recursive self-improvement risks
- National security agencies concerned about autonomous capability gain
Expect public debates about whether self-improving AI should require special oversight or disclosure.
4. Gemini Overtakes ChatGPT in MAUs by Q3 2026
Google’s growth trajectory (100M users in 3 months) combined with:
- Tighter Android/Search integration
- More affordable pricing ($7.99 vs $20/month)
- Workspace embedding
…could push Gemini past ChatGPT’s ~810M users within 6 months.
ChatGPT still leads in “power user” engagement, but raw user count may flip.
5. The “Vibe Working” Era Begins
Anthropic’s Scott White coined the term “vibe working”—the evolution of “vibe coding” where people accomplish complex professional work by describing intent to AI teams rather than executing tasks manually.
By year-end, expect:
- Financial analysts to “vibe work” full earnings models
- Lawyers to “vibe work” contract drafts and legal research
- Product managers to “vibe work” PRDs, specs, and roadmaps
- Marketers to “vibe work” campaigns from concept to execution
This represents a fundamental shift in how knowledge work happens—closer to directing a team than performing individual tasks.
How to Prepare: Practical Action Steps
For Individual Professionals
If you write code:
- Master both Claude and Codex: Each excels in different scenarios; learn when to use each
- Learn agent orchestration: Platforms like LangChain, AutoGen, and Claude Agent SDK
- Build AI review skills: Catching AI mistakes is more valuable than writing perfect code
- Document intent, not implementation: Focus on what you want, let AI handle how
If you do knowledge work:
- Experiment with agent workflows: Use Claude Opus 4.6’s Cowork for research, analysis, document creation
- Develop delegation skills: Clearly articulating objectives to AI is the new core competency
- Invest in AI literacy: Understand capabilities and limitations to use tools effectively
- Stay human-in-the-loop: Review AI outputs critically; don’t blindly trust
For Engineering Leaders
Short-term (Next 90 days):
- Pilot agent-based development: Choose low-risk internal tools to test Opus 4.6 or Codex workflows
- Establish AI code review processes: Define what human reviewers must check in AI-generated code
- Measure productivity gains: Track velocity improvements and quality metrics
- Train teams: Invest in workshops on effective AI delegation and oversight
Medium-term (Rest of 2026):
- Refactor for AI-native architecture: Design systems that AI can easily introspect and modify
- Build AI governance frameworks: Policies for when AI can commit directly vs require review
- Optimize costs: Context-heavy agent workflows can get expensive; implement monitoring
- Plan for self-improving systems: Evaluate whether your organization will adopt or avoid them
For Business Executives
Strategic decisions:
- Assess build-vs-buy: Custom software is now 10-100x cheaper; reconsider what you outsource
- Invest in AI infrastructure: Agent workflows require compute, storage, and orchestration platforms
- Rethink workforce planning: Roles shift from execution to oversight; plan reskilling
- Evaluate vendor lock-in: Choosing Claude vs Codex vs Gemini has long-term strategic implications
Competitive positioning:
- Identify AI-native opportunities: What becomes possible when development costs drop 10x?
- Accelerate experimentation: Faster iteration enables more bets on new products/features
- Monitor regulatory landscape: Self-improving AI may trigger new compliance requirements
- Build AI culture: Organizations that embrace AI-native workflows gain compounding advantages
The Bottom Line: We Just Entered a New Era
February 4-5, 2026 wasn’t just another week of AI announcements. It marked an inflection point where:
✅ AI agents evolved from assistants to autonomous teams that collaborate like human workers
✅ Models began building themselves through self-bootstrapping feedback loops
✅ AI became infrastructure embedded in billions of devices rather than standalone products
✅ Adoption hit mainstream scale with 750M+ users on single platforms
The question is no longer “Can AI do X?” but “How quickly will AI transform every aspect of how we work?”
The companies and individuals who recognize this shift and adapt fastest will define the next decade of technology. Those who wait will find themselves obsolete not in years, but in quarters.
The AI revolution isn’t coming. It arrived this week.
Frequently Asked Questions (FAQ)
Which model is better, Claude Opus 4.6 or GPT-5.3-Codex?
It depends on your use case. Claude Opus 4.6 excels at complex multi-agent workflows, long-context tasks (1M tokens), and defensive coding for high-stakes applications. GPT-5.3-Codex is faster (30-40% quicker implementation), more concise, and better at logical reasoning for algorithmic problems. Most developers will benefit from using both depending on the specific task.
Can I use agent teams on Claude right now?
Yes. Claude Opus 4.6’s agent teams are available now in Claude Code as a research preview for Claude Max, Team, and Enterprise plans. You can spin up multiple agents that work in parallel on independent subtasks, with human oversight through Shift+Up/Down controls or tmux.
What does “self-bootstrapping” really mean for GPT-5.3-Codex?
Self-bootstrapping means earlier versions of GPT-5.3-Codex helped develop later versions by analyzing training logs, flagging failing tests, suggesting fixes, generating deployment code, and summarizing evaluation results. This is AI-in-the-loop development, not unsupervised AI rewriting its own code. Humans remain in control with guardrails and version management.
How did Gemini reach 750 million users so fast?
Google’s distribution advantage. Gemini is deeply integrated into Google Search, Android devices (3+ billion), Google Workspace (Docs, Sheets, Gmail), YouTube, Chrome, and Maps. Unlike ChatGPT or Claude that require visiting separate websites, Gemini is already where billions of people work and browse. This embedded approach drives adoption faster than standalone products.
Is AI going to replace software developers?
No, but the role is transforming. Developers are shifting from writing every line of code to orchestrating AI agents, reviewing AI-generated code, catching edge cases, and making architectural decisions. The skill set is evolving from “how to implement X” to “how to effectively delegate to AI and ensure quality.” Demand for skilled developers remains high—but the definition of “skilled” is changing rapidly.
How much does Claude Opus 4.6 and GPT-5.3-Codex cost?
Claude Opus 4.6 API pricing:
- Standard: $5 input / $25 output per million tokens
- 1M context premium: $10 input / $37.50 output per million tokens (>200k tokens)
GPT-5.3-Codex:
- Included with ChatGPT Plus ($20/month), Team, and Enterprise plans
- API pricing not yet announced (coming soon)
Both offer free trials through their respective chatbot interfaces (claude.ai and ChatGPT).
Can I test these models for free?
Claude Opus 4.6:
- Free tier available at claude.ai with rate limits
- Paid plans start at $20/month (Claude Max)
GPT-5.3-Codex:
- Requires paid ChatGPT plan (Plus $20/month minimum)
- Free ChatGPT account uses older models
Gemini:
- Free tier available in Google Search and Gemini app
- Gemini Advanced ($19.99/month for older plans, new $7.99 AI Plus plan)
Are agent teams safe for production use?
Agent teams are currently in research preview, meaning Anthropic is still refining the feature based on early user feedback. While companies like Rakuten, GitHub, and Asana are using Opus 4.6 in production, agent teams should be tested thoroughly in non-critical environments first. Implement human review checkpoints for high-stakes decisions until the feature reaches general availability and your team has established confidence in its reliability.
Will self-improving AI lead to AGI or runaway intelligence?
Current self-bootstrapping is narrowly scoped: GPT-5.3-Codex improved its own training and deployment, not its fundamental architecture or goals. This is a far cry from the “recursive self-improvement” scenario where AI autonomously redesigns itself. That said, researchers like Gary Marcus warn that even bounded self-improvement introduces risks of bootstrap bias and specification gaming. Robust testing, diverse benchmarks, and independent audits remain essential.
How Kersai Can Help You Navigate the AI Agent Era
At Kersai, we help organizations cut through AI hype and implement strategies that deliver real business value in this rapidly evolving landscape.
AI Strategy & Implementation
- Agent workflow design: Build multi-agent systems optimized for your specific use cases
- Model selection guidance: Choose the right model (Claude, Codex, Gemini) for each task
- Pilot program development: Test agent-based development on low-risk projects before scaling
- ROI measurement: Track productivity gains, cost savings, and quality metrics
AI Governance & Risk Management
- Code review frameworks: Establish processes for reviewing AI-generated deliverables
- AI oversight training: Develop skills to catch AI mistakes and edge cases
- Compliance assessment: Ensure AI-generated work meets regulatory requirements
- Security auditing: Identify vulnerabilities in AI-generated code and systems
Thought Leadership & Content
- Expert AI analysis: We translate complex breakthroughs into strategic insights
- Authority building: Position your brand as a trusted voice on AI and emerging technology
- SEO-optimized content: Drive organic traffic with comprehensive, data-driven articles
- Competitive intelligence: Stay ahead of AI developments that impact your industry
Ready to harness the power of AI agent teams, self-improving systems, and AI-native workflows? Contact us to discuss your AI strategy, or subscribe to our newsletter for weekly insights on AI breakthroughs, practical implementation guidance, and competitive intelligence.
Key Takeaways
✅ Claude Opus 4.6 introduced agent teams that collaborate autonomously, 1M token context, and leads benchmarks across coding, finance, legal, and knowledge work
✅ GPT-5.3-Codex is the first model to help build itself through self-bootstrapping, running 25% faster while combining frontier coding with GPT-5 reasoning
✅ Google Gemini hit 750M monthly active users (+100M in 3 months), positioning it as the #2 AI chatbot globally
✅ Agent teams enable horizontal scaling (more parallel workers) while self-bootstrapping enables vertical scaling (recursive capability improvement)
✅ Real-world testing shows Opus 4.6 excels at defensive coding and complex tasks; Codex is 30-40% faster with better integration
✅ Three paradigms reshaping AI: multi-agent collaboration, self-improving systems, and AI as infrastructure rather than standalone product
✅ The AI development cycle has compressed from quarters to days—competitive pressure is intensifying exponentially
✅ “Vibe working” era beginning where professionals delegate complex work to AI agent teams rather than executing tasks manually
✅ Developers must shift from writing code to orchestrating AI agents and ensuring quality through review and oversight
About the Author: This analysis was prepared by Kersai’s AI research team, combining technical assessment, competitive analysis, and strategic implications for businesses and developers. We help organizations navigate rapidly evolving AI technologies with expert guidance on strategy, implementation, and thought leadership.