
AI Breakthroughs in 2026: March Update
Published: March 12, 2026 | By the Kersai Research Team | Reading Time: ~20 minutes
Quick Summary: GPT-5.4 has officially surpassed human performance on desktop task benchmarks. Yann LeCun — the “godfather of deep learning” — raised $1 billion and left Meta to build a completely different kind of AI. MIT published a model that could slash billions from drug development costs. DeepSeek V4 launched with 1 trillion parameters and open weights. And the global AI model release cadence has accelerated to one major launch every 72 hours. This is your definitive March 2026 AI breakthroughs update.
Table of Contents
- The State of AI in March 2026
- Breakthrough #1: GPT-5.4 Surpasses Human Performance
- Breakthrough #2: Yann LeCun Leaves Meta and Raises $1 Billion for World Models
- Breakthrough #3: MIT’s AI Model Slashes Drug Development Costs
- Breakthrough #4: DeepSeek V4 — Open-Source Trillion-Parameter AI
- Breakthrough #5: The Model Release Velocity Crisis
- The Full 2026 Benchmark Scoreboard
- What These Breakthroughs Mean for Businesses
- FAQ
1. The State of AI in March 2026
At the start of 2026, the consensus forecast among AI analysts was measured: incremental improvements to existing frontier models, gradual enterprise adoption, and cautious progress on AI agents and automation.
Twelve weeks in, that forecast looks embarrassingly conservative.
The first quarter of 2026 has produced:
- The first AI model to surpass human performance on real-world desktop task benchmarks.
- The departure of one of the three most influential AI researchers alive — Yann LeCun — from Meta, followed immediately by a $1 billion funding round for a radically different approach to AI.
- A scientific breakthrough at MIT that could eliminate billions of dollars in pharmaceutical R&D costs.
- The open-source release of a 1-trillion-parameter Chinese AI model competitive with every US frontier model.
- A release velocity of 255+ model updates in Q1 alone — averaging one significant release every 72 hours.
The pace is not slowing. If anything, the competitive dynamics across US labs, Chinese labs, and the open-source community are accelerating the timeline on nearly every metric that AI researchers track.
This article covers the five most significant AI breakthroughs of March 2026 in depth — what they are, why they matter, and what they mean for businesses and individuals navigating the AI era.
2. Breakthrough #1: GPT-5.4 — The First AI to Beat Humans at Using Computers
2.1 What happened
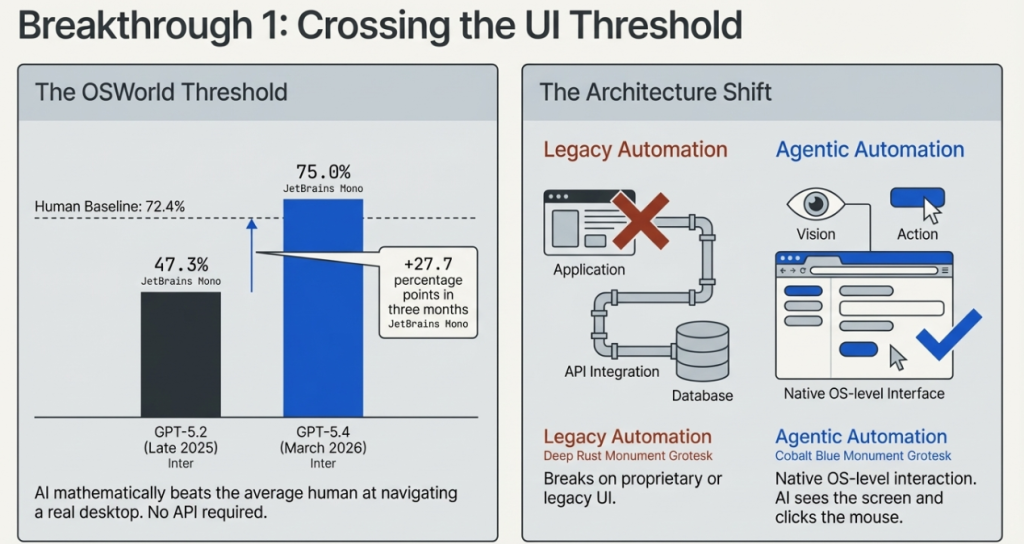
On March 4, 2026, OpenAI released GPT-5.4 — and with it, published benchmark results that crossed a threshold AI researchers had been tracking for years.
On OSWorld-Verified — the benchmark that measures how effectively an AI can navigate a real desktop environment using screenshots, keyboard actions, and mouse clicks — GPT-5.4 achieved a 75.0% success rate.
The human baseline on the same benchmark is 72.4%.
For the first time, an AI model has demonstrably surpassed average human performance at using a computer.
2.2 Why OSWorld matters more than other benchmarks
The AI industry has a long history of benchmark saturation — models quickly reach near-perfect scores on academic tests that turn out not to reflect real-world capability. OSWorld is different for three reasons.
First, it tests real computer use, not language tasks. The AI is given a Windows or macOS desktop environment and must complete genuine tasks — opening applications, navigating interfaces, filling forms, writing and executing code, managing files — using the same visual interface a human would use. There is no API access, no special integration. The AI sees a screen and acts.
Second, the tasks are verified. Each task has a deterministic pass/fail outcome — either the correct file was created, the correct email was sent, the correct code was executed. There is no subjective scoring.
Third, the human baseline was established by real users completing the same tasks. It is a genuine comparison, not a theoretical one.
GPT-5.4’s 75.0% beating humans’ 72.4% is a narrow margin — but it is a real one, on a benchmark designed to prevent the kind of gaming that inflates scores on academic tests.
2.3 The full GPT-5.4 benchmark picture
The OSWorld result is the headline, but GPT-5.4’s broader benchmark performance represents OpenAI reclaiming leadership across the board after months of competitive pressure from Claude Opus 4.6, Gemini Ultra, and DeepSeek V4.
| Benchmark | GPT-5.4 | GPT-5.2 | Change | What It Measures |
|---|---|---|---|---|
| OSWorld-Verified | 75.0% | 47.3% | +27.7pp | Desktop computer use |
| WebArena-Verified | 67.3% | 65.4% | +1.9pp | Browser-based task completion |
| Online-Mind2Web | 92.8% | 78.3% | +14.5pp | Web navigation and interaction |
| ARC-AGI-2 | 73.3% | 52.9% | +20.4pp | Novel reasoning and adaptation |
| GPQA Diamond | 92.8% | 88.1% | +4.7pp | Graduate-level scientific reasoning |
| GDPval | 83.0% | 70.9% | +12.1pp | Knowledge work across professions |
| HLE (with tools) | 53.8% | 45.5% | +8.3pp | Humanity’s last exam |
| SWE-Bench Pro | 57.7% | 43.2% | +14.5pp | Real-world software engineering |
| Terminal-Bench 2.0 | 75.1% | 61.4% | +13.7pp | Command-line and terminal tasks |
| BrowseComp | 82.7% | 65.8% | +16.9pp | Multi-step web research |
| MMMU-Pro | 81.2% | 74.6% | +6.6pp | Visual understanding and reasoning |
Source: OpenAI (March 4, 2026)
2.4 Key new capabilities
Beyond benchmarks, GPT-5.4 introduces several capabilities that represent genuine architectural advances:
Native computer use at the OS level
GPT-5.4 can interact with any software application on any desktop operating system — not through a custom API integration, but through the same visual interface a human uses. This is the technical foundation for AI agents that can operate any piece of software without requiring custom integration work.
1-million-token context window
The API version of GPT-5.4 supports a 1-million-token context window — matching the long-context capability that DeepSeek V4 introduced last week and enabling the analysis of entire codebases, legal document libraries, or research archives in a single session.
47% token efficiency improvement
GPT-5.4 solves the same problems as GPT-5.2 using 47% fewer tokens, on average. For high-volume enterprise deployments, this translates directly to lower API costs — potentially halving the inference cost of equivalent workloads.
Thinking variant for deep reasoning
A specialised “GPT-5.4 Thinking” variant applies extended chain-of-thought reasoning for complex multi-step problems — mathematics, scientific reasoning, strategic planning — before producing its final output.
2.5 What surpassing human computer use actually means
The 75.0% vs 72.4% comparison deserves careful interpretation. It does not mean AI can do everything a human can do on a computer. The benchmark tests a specific set of defined tasks under specific conditions. Humans would likely outperform the AI on highly contextual, judgment-intensive, or novel tasks not represented in the benchmark.
What it does mean:
- For defined, repeatable computer-based tasks — the kind that make up a significant portion of white-collar knowledge work — AI has crossed the threshold of human-level performance.
- The gap will continue to widen. GPT-5.2 scored 47.3% on OSWorld. GPT-5.4 scores 75.0%. That is a 27.7 percentage point improvement in roughly three months. If the trajectory continues, human performance will be a distant rearview mirror within a year.
- Agentic AI that operates computer interfaces — not just APIs — is now commercially viable for a range of enterprise workflows. Every task that a human currently performs by clicking through a screen interface is now a candidate for AI automation.
3. Breakthrough #2: Yann LeCun Leaves Meta and Raises $1 Billion for a Different Kind of AI

3.1 Who is Yann LeCun and why this matters
To understand why LeCun’s departure from Meta and his $1 billion fundraise is genuinely significant — rather than just another well-funded AI startup story — you need to understand who he is.
Yann LeCun is one of three researchers awarded the Turing Award (the Nobel Prize of computer science) for foundational contributions to deep learning. The three laureates — LeCun, Geoffrey Hinton, and Yoshua Bengio — are collectively known as the “godfathers of deep learning.” Their work in the 1980s and 1990s, dismissed as fringe for decades, became the foundation of everything from image recognition to large language models.
LeCun spent 10 years as Chief AI Scientist at Meta, where he built and led FAIR — Meta’s Fundamental AI Research laboratory, one of the most productive and influential AI research organisations in the world. FAIR produced PyTorch (the dominant AI research framework), LLaMA (the open-source model that triggered the open-source AI movement), and dozens of foundational research contributions.
He left Meta in November 2025.
In March 2026, he raised $1.03 billion for his new venture: AMI Labs (Advanced Machine Intelligence).
3.2 What AMI Labs is building — and why it is different
AMI Labs is not building another large language model. That distinction is deliberate, documented, and philosophically important.
LeCun has been one of the most prominent and persistent critics of the LLM approach to AI. His core argument, published in a widely-read 2022 paper and reiterated throughout his tenure at Meta, is:
Language models learn about the world only through text. But most of what a human or animal knows about the world was not learned from text — it was learned through physical interaction, sensory experience, and observation of how the world actually works.
The implication: no matter how much you scale a language model, it will always be missing the kind of grounded, physical understanding of reality that enables genuine intelligence — the ability to plan reliably, reason about novel physical situations, and understand causality rather than just correlation.
World models are LeCun’s alternative. Rather than predicting the next token in a text sequence, world models learn abstract representations of how the real world behaves — how objects move, how forces interact, what actions produce what consequences. They are trained on sensory data (video, sensors, physical interactions) rather than text, and their internal representations capture the structure of reality rather than the structure of language.
3.3 The $1.03 billion raise
AMI Labs raised $1.03 billion at a $3.5 billion pre-money valuation in a seed round — the largest seed round in AI history. The company was founded earlier in 2026 and is headquartered in Paris, with research hubs in New York (where LeCun teaches at NYU), Montreal, and Singapore.
Key facts about the company and the raise:
- No plans for revenue in the near term. AMI Labs is explicitly a fundamental research company, not an applied AI startup.
- Will publish papers and open-source code as it develops — unusual for a well-funded commercial AI lab in 2026.
- Aims to build AI that “understands the world, has persistent memory, can reason and plan, and is controllable and safe.”
- Will engage with enterprise clients early to ground research in real-world scenarios and data — but commercial products are likely years away.
3.4 The “world model” concept explained simply
The easiest way to understand world models is by contrast with language models.
A language model is trained on text. It learns that “if you drop a glass, it breaks” because that sentence (or ones like it) appears in its training data. It knows about gravity and fragility through the language used to describe them — not through having any representation of what gravity or fragility actually are.
A world model is trained on sensory observations of reality. It learns that dropped glasses break by observing thousands of instances of objects falling — building an internal model of how forces, materials, and trajectories interact. It does not just know the words; it has a representation of the underlying physics.
The practical consequence: a world model can generalise to novel physical situations it has never seen described in text. A language model can describe what would happen if you dropped a glass made of a new material — but only if similar scenarios appear in its training text. A world model can reason about it from first principles.
This matters most for:
- Robotics and physical AI: World models are essential for robots that need to manipulate objects, navigate environments, and plan physical actions reliably.
- Scientific AI: Drug discovery, materials science, and climate modelling require physical reasoning that language models approximate poorly.
- Genuine planning and reasoning: The ability to plan action sequences that reliably achieve physical goals is foundational to the kind of AI agency that current LLM-based systems still struggle with.
3.5 The significance for the AI industry
AMI Labs represents something rare in 2026: a well-capitalised bet against the dominant paradigm.
Every major AI lab — OpenAI, Anthropic, Google DeepMind, Meta (post-LeCun), Mistral, DeepSeek — is betting that scaling language and multimodal models is the path to general AI capability. LeCun’s departure and AMI Labs’ launch is the most prominent and best-funded dissenting view.
Whether world models ultimately prove more capable than scaled LLMs is a question that will not be answered in months — AMI Labs’ CEO acknowledges it could take years. But the $1.03 billion vote of confidence in the alternative approach is the clearest signal yet that the AI research community’s consensus on the path to general AI is less settled than the dominant narrative suggests.
4. Breakthrough #3: MIT’s AI Reinvents Drug Discovery
4.1 The problem it solves
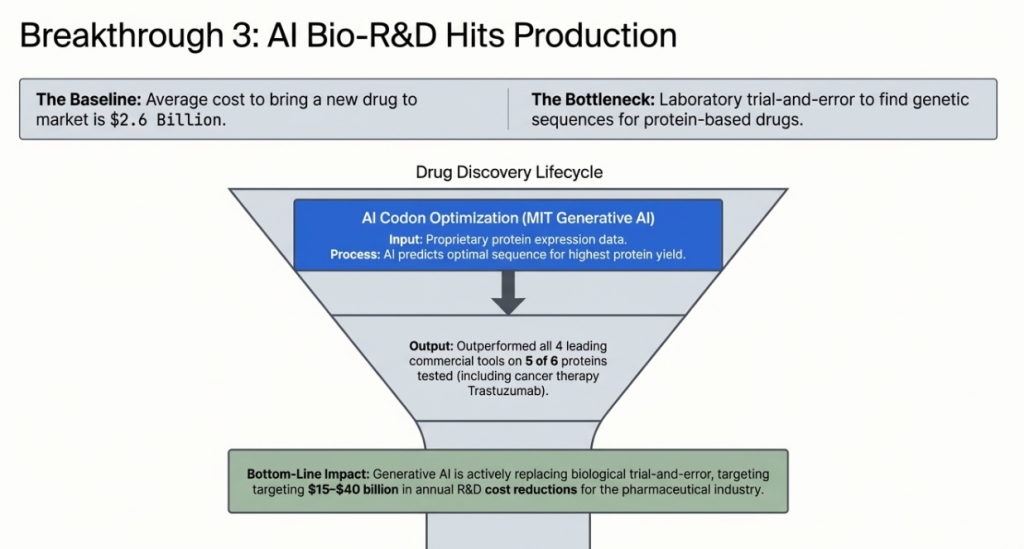
Drug development is one of the most expensive and uncertain processes in modern industry. The average cost of bringing a new drug to market exceeds $2.6 billion — and the majority of that cost is absorbed in the early stages of development, where researchers are trying to identify and optimise molecules that will work as intended in the human body.
For protein-based drugs — biologics including antibiotics, cancer therapies, and treatments for rare genetic diseases — a critical early challenge is codon optimisation: determining the precise genetic sequence that will cause an industrial organism (typically yeast) to produce the target protein at the desired quantity and quality.
The wrong codon sequence produces too little protein, or protein that folds incorrectly, or protein that is unstable. Finding the right sequence involves enormous laboratory trial and error — testing thousands of variants to find the ones that work. It is slow, expensive, and routinely takes months or years before a drug can even enter the pipeline.
4.2 What MIT built
On February 16, 2026, MIT researchers published results from a new generative AI model designed specifically for codon optimisation and protein production prediction.
The model was trained on a proprietary dataset of protein expression data — the results of thousands of laboratory experiments correlating genetic sequences with protein production outcomes. Using this training data, it learned to predict which codon sequences will produce the highest protein yields for a given target molecule.
The results when tested on six therapeutically significant proteins — including human growth hormone, human serum albumin, and trastuzumab (a widely-used cancer therapy):
| Protein | MIT Model Rank | Against 4 Commercial Tools |
|---|---|---|
| Human growth hormone | 1st | Exceeded all competitors |
| Human serum albumin | 1st | Exceeded all competitors |
| Trastuzumab (cancer therapy) | 1st | Exceeded all competitors |
| IL-2 (immune therapy) | 1st | Exceeded all competitors |
| Erythropoietin | 1st | Exceeded all competitors |
| FGF-21 (metabolic therapy) | 2nd | Close second to best competitor |
The MIT model outperformed all four leading commercial codon optimisation tools on five of six proteins tested.
4.3 Why this is a genuine breakthrough
Three things distinguish this result from the routine stream of AI-in-biology announcements:
First, the comparison baseline is serious. The four commercial codon optimisation tools MIT compared against are the same tools currently used by major pharmaceutical companies in production drug development. These are not toy models — they represent the current state of commercial practice. Beating all of them on five of six proteins is a meaningful result.
Second, the application is directly commercial. Codon optimisation happens at the very beginning of the biologics development pipeline. A model that consistently identifies better sequences earlier means every subsequent stage of development — laboratory testing, clinical trials, manufacturing scale-up — starts from a higher-quality baseline. The cost savings compound across the entire pipeline.
Third, it points toward a broader paradigm shift. The MIT model is one instance of a broader trend: AI systems trained on experimental biological data are beginning to outperform both human expert intuition and existing computational tools at specific, high-value tasks in drug discovery. AlphaFold transformed protein structure prediction. BoltzGen extended that capability to novel drug design. The MIT codon optimisation model represents another step in the systematic AI-driven replacement of expensive biological laboratory trial-and-error.
4.4 The commercial implication
The pharmaceutical industry spent approximately $260 billion on R&D globally in 2025. A significant portion of that spend is in the early discovery and optimisation stages that AI tools like MIT’s model are beginning to address.
Consulting firm analysts estimate that AI-driven improvements in early-stage biologics development could reduce industry-wide R&D costs by $15–40 billion annually over the next decade — primarily by reducing the laboratory work required to identify viable drug candidates.
For investors, enterprises, and policymakers tracking the AI impact on specific industries, drug discovery is one of the clearest cases of AI delivering measurable, near-term commercial value — not as a future promise, but as a present reality.
5. Breakthrough #4: DeepSeek V4 — The Open-Source Trillion-Parameter Rival
5.1 The launch
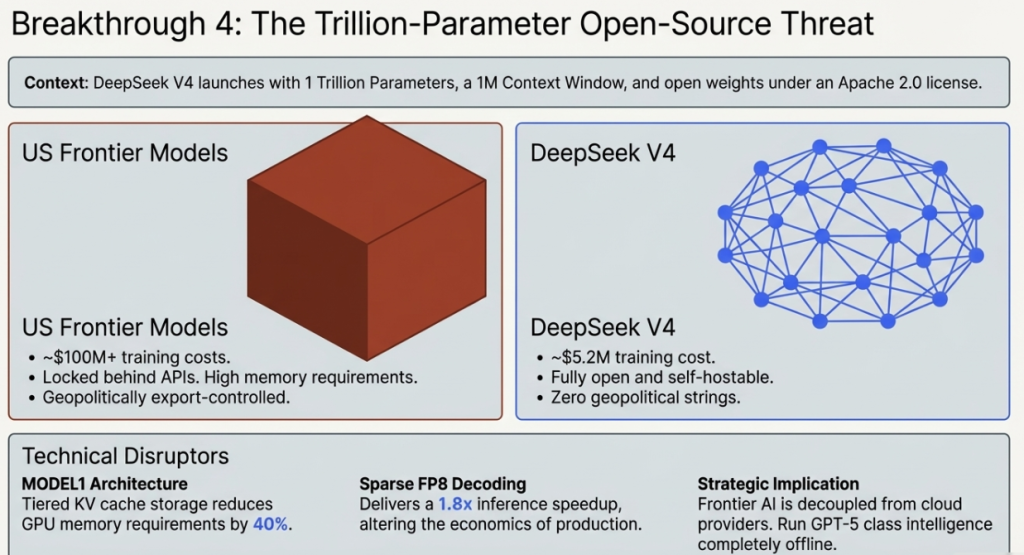
On March 3, 2026, DeepSeek — the Hangzhou-based AI lab founded by the Chinese quantitative hedge fund High-Flyer — released DeepSeek V4: a 1-trillion-parameter model with open weights, a 1-million-token context window, and native multimodal support across text, code, vision, and audio.
The model is free to download. Free to run. Free to modify. No commercial licence required. No API fees. No data leaving to DeepSeek’s servers if you self-host.
5.2 Technical specifications
| Specification | DeepSeek V4 | Notes |
|---|---|---|
| Total parameters | 1 trillion | Sparse MoE: 32B active per forward pass |
| Context window | 1,000,000+ tokens | Genuine recall via Engram architecture |
| Modalities | Text, code, vision, audio | Native multimodal, single model |
| Weights | Fully open | Apache 2.0 licence |
| Estimated training cost | ~$5.2 million | vs $100M+ for US frontier models |
| Memory reduction | 40% vs equivalent scale | Via MODEL1 architecture |
| Inference speedup | 1.8× vs V3 | Via sparse FP8 decoding |
| Training efficiency gain | 30% vs V3 | Via improved pre-training curriculum |
5.3 Benchmark performance vs US frontier models
| Benchmark | DeepSeek V4 | GPT-5.4 | Claude Opus 4.6 | What It Measures |
|---|---|---|---|---|
| MMLU | 91.4% | 93.2% | 91.8% | General knowledge |
| HumanEval | 94.7% | 93.2% | 92.1% | Coding ability |
| MATH | 88.9% | 91.4% | 90.2% | Mathematical reasoning |
| GPQA | 79.3% | 92.8% | 86.4% | Graduate science |
| Long-context (1M token) | Best in class | Competitive | Below par | Million-token recall |
Sources: Hugging Face, LMSys, independent evaluations, March 2026
5.4 The four technical innovations
MODEL1 Architecture: A new memory management system using tiered KV cache storage that reduces GPU memory requirements by approximately 40% compared to equivalent-scale models. A model previously requiring 8× H100 GPUs can now run on 5.
Sparse FP8 Decoding: A quantisation approach delivering 1.8× inference speedup without meaningful quality degradation — making high-throughput production deployments dramatically more economical.
Enhanced Pre-Training Curriculum: Refined data curation and training pipeline that achieves frontier-competitive performance at approximately $5.2 million in training cost — roughly 1/20th of comparable US model training budgets.
Engram Architecture: A learned hierarchical memory retrieval system that enables genuine performance across million-token context windows. Unlike competitors that claim large context windows but degrade on mid-document information, Engram maintains consistent retrieval quality across the full context.
5.5 The geopolitical dimension
DeepSeek V4 arrives in the same week that the US government is considering chip export rules designed to restrict Chinese AI development by requiring investment fees for Nvidia GPU access.
The gap between the policy intent and the observable outcome is stark:
- US export controls restrict Chinese access to the most advanced Nvidia chips.
- DeepSeek V4 was trained for $5.2 million using techniques that work around hardware constraints.
- The model is then released as open weights — meaning every developer on Earth can run it for free, with no ongoing Chinese dependency.
- You cannot export-control a model that is already downloaded.
For the 125+ countries that sit outside the US-China binary — the Global South, Southeast Asia, Eastern Europe, Latin America — DeepSeek V4 offers frontier AI capability with no geopolitical strings attached, no investment fees, and no classified obligations. This is the strategic context that makes every DeepSeek release more significant than its raw benchmark scores suggest.
6. Breakthrough #5: The Model Release Velocity Crisis
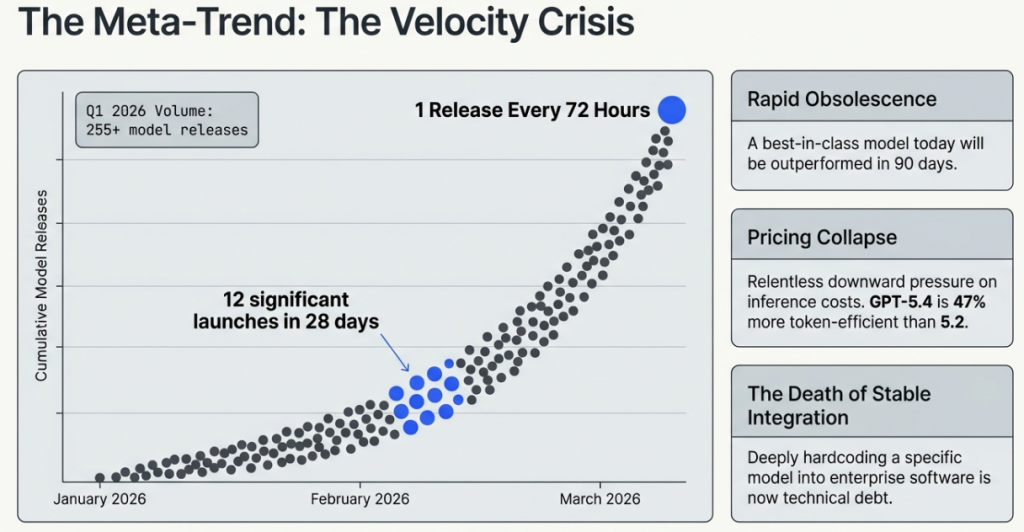
6.1 The numbers
The fifth breakthrough of March 2026 is not a single model or research result. It is a meta-trend that is reshaping how every organisation should think about AI strategy.
According to LLM Stats, the AI model tracking platform:
- Q1 2026 has already produced 255+ model releases across major AI organisations — tracking toward over 1,000 releases in 2026 across the industry.
- February 2026 alone produced 12 significant model releases from major labs: Gemini 3.1 Pro, Claude Opus 4.6, Claude Sonnet 4.6, GPT-5.3 Codex, Grok 4.20, Qwen 3.5, Mercury 2, ByteDance Seed 2.0 Lite and Pro, MiniMax M2.5, GLM-5, and LongCat-Flash-Lite.
- March 2026 is on pace to match or exceed February.
- The release cadence has accelerated from approximately one major release every 6 months in 2024 to one significant release every 72 hours in Q1 2026.
6.2 What this means practically
The acceleration in release velocity has four direct implications for organisations building on AI:
Rapid performance obsolescence: A model that represents best-in-class performance today may be significantly outperformed within 90 days. Enterprise AI strategies that assume stable model performance over 12–24 month contract cycles are increasingly disconnected from reality.
Evaluation overhead: With a significant new model available every 72 hours, organisations face a growing evaluation burden. Testing new models against production workloads is time-consuming, and the pace of releases now exceeds most organisations’ capacity to evaluate them systematically.
Pricing pressure and opportunity: Competition at this velocity creates sustained downward pressure on AI API pricing. GPT-5.4 is already 47% more token-efficient than GPT-5.2. Enterprise customers who renegotiate contracts annually are leaving significant savings on the table.
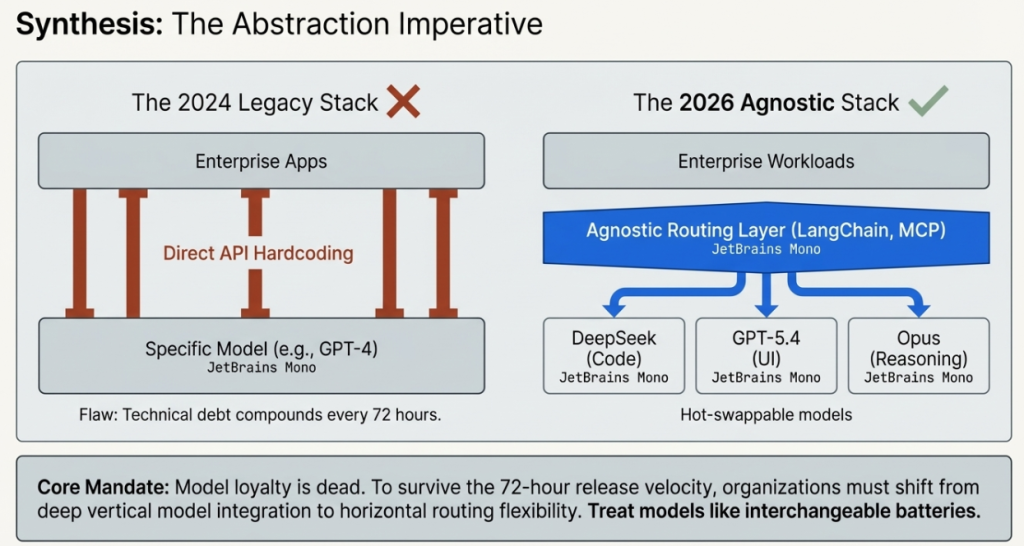
The abstraction layer imperative: The only viable organisational response to this velocity is to build abstraction layers between your applications and specific model versions. Hardcoded dependencies on specific models create technical debt that compounds at the pace of the release cycle. Model-agnostic architectures — using frameworks like LangChain, LlamaIndex, or custom abstraction layers built on MCP — allow you to swap and upgrade models without rebuilding your applications.
6.3 The release velocity forecast
Based on current trajectories from each major lab, the remainder of 2026 is likely to bring:
| Lab | Expected Q2–Q4 2026 Releases | Likely Highlights |
|---|---|---|
| OpenAI | GPT-5.5, GPT-6 preview, o4 reasoning series | AGI-adjacent capability claims likely |
| Anthropic | Claude Opus 5, Claude Sonnet 4.7, specialised verticals | Safety architecture announcements |
| Google DeepMind | Gemini 3.2, Gemini 4 preview, Nano Banana 3 | Multimodal and device-level breakthroughs |
| Meta | LLaMA 4 series (open weights) | Open-source ecosystem expansion |
| DeepSeek | V4.5, V5 expected | Cost and efficiency records |
| Mistral | Multiple releases | European open-source leadership |
| Chinese labs (aggregate) | 50+ releases | OpenRouter dominance expansion |
The consensus among AI analysts: the first half of 2026 will likely see the first credible claims of AGI-adjacent performance on complex, multi-domain professional tasks — not necessarily “true AGI,” but models capable of performing the full range of knowledge work tasks at expert-human level across a meaningful number of professional domains.
7. The 2026 AI Benchmark Scoreboard: March Edition
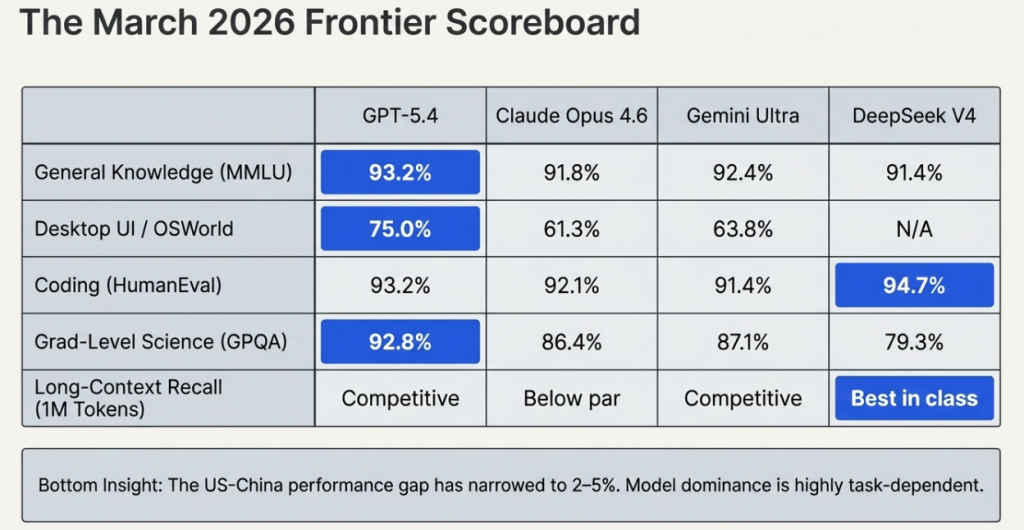
The following table represents the most complete publicly available benchmark comparison across frontier models as of March 12, 2026. All figures sourced from official lab publications or independent evaluation platforms (Hugging Face, LMSys, Scale AI).
| Benchmark | GPT-5.4 | Claude Opus 4.6 | Gemini Ultra | DeepSeek V4 | What It Tests |
|---|---|---|---|---|---|
| MMLU | 93.2% | 91.8% | 92.4% | 91.4% | General knowledge |
| GPQA Diamond | 92.8% | 86.4% | 87.1% | 79.3% | Grad-level science |
| HumanEval | 93.2% | 92.1% | 91.4% | 94.7% | Coding |
| SWE-Bench Pro | 57.7% | 52.3% | 49.8% | 55.1% | Real software engineering |
| ARC-AGI-2 | 73.3% | 68.9% | 70.2% | 66.4% | Novel reasoning |
| MATH | 91.4% | 90.2% | 89.7% | 88.9% | Mathematical reasoning |
| OSWorld (Computer Use) | 75.0% | 61.3% | 63.8% | N/A | Desktop task completion |
| GDPval | 83.0% | 77.4% | 79.1% | N/A | Professional knowledge work |
| BrowseComp | 82.7% | 71.2% | 74.3% | N/A | Multi-step web research |
| Long-context (1M tokens) | Competitive | Below par | Competitive | Best in class | Million-token recall |
| HLE (with tools) | 53.8% | 48.2% | 50.1% | 47.6% | Humanity’s last exam |
Human baseline for reference: OSWorld 72.4%; GPQA Diamond approximately 65%; HLE approximately 8%
Key takeaways from the March 2026 scoreboard:
- GPT-5.4 leads overall and holds the most benchmark records, particularly on computer use and professional knowledge work.
- DeepSeek V4 leads on coding (HumanEval) and long-context recall — the two benchmarks most relevant to software engineering workflows.
- Claude Opus 4.6 remains competitive on reasoning tasks and maintains the lead in safety and alignment evaluations not shown here.
- All four models now significantly exceed human performance on GPQA Diamond (graduate-level science) and HLE (humanity’s last exam).
- The performance gap between US frontier models and top Chinese open-source models has narrowed to within 2–5 percentage points on most benchmarks — a gap that DeepSeek V5 could close or reverse.
8. What These Breakthroughs Mean for Businesses
8.1 Computer use changes automation economics
GPT-5.4’s OSWorld result is the most practically significant development of the month for businesses currently assessing AI automation investments.
Every enterprise workflow that consists of a human navigating screen interfaces — clicking through dashboards, copying data between applications, filling forms, running reports — is now a candidate for AI automation at a cost and reliability level that was not commercially viable six months ago.
The key distinction: this automation does not require API integration. The AI works through the visual interface, exactly like a human. For legacy systems with no API, vendor-locked software, or complex multi-application workflows, this is a fundamental change in what is automatable.
What to do: Identify your highest-volume, most repetitive screen-navigation workflows and assess them against GPT-5.4’s computer use capability. Start with supervised automation (human monitors AI performance) before scaling to autonomous operation.
8.2 World models are a long-term bet worth watching now
AMI Labs will not ship a commercial product this year. World models as a production technology are likely 2–4 years away at commercial scale.
But Yann LeCun’s departure from Meta and the $1.03 billion raise are signals that the AI research community’s most credentialed critic of LLMs has decided the alternative approach is viable enough to build a company around.
For enterprises making long-term AI platform decisions — particularly those in robotics, physical automation, drug discovery, and climate modelling — tracking the AMI Labs research output is worth the attention. If world models deliver on LeCun’s thesis, the current LLM-based tools will be a transitional technology.
What to do: Subscribe to AMI Labs’ research publication feed. Evaluate your AI strategy’s reliance on LLM-specific capabilities vs capabilities that world models might supersede. Maintain optionality in your long-term AI architecture.
8.3 Drug discovery AI is ready for enterprise adoption now
The MIT codon optimisation result, combined with AlphaFold 3, BoltzGen, and the broader AI drug discovery ecosystem, establishes something that would have been speculative 18 months ago:
AI-driven tools for early-stage biologics development are now commercially superior to the tools that major pharmaceutical companies are currently using.
For pharmaceutical companies, biotech startups, and healthcare enterprises, the question is no longer whether to adopt AI in drug discovery — it is how to integrate these tools into existing pipelines and how to ensure your biology data assets are structured to train and fine-tune specialised models.
What to do: Audit your current computational biology toolchain against the AI alternatives. Prioritise codon optimisation, protein structure prediction, and binding affinity prediction as the three areas where AI tools now offer clear commercial advantages over legacy computational methods.
8.4 Build for model velocity, not model stability
The 255+ Q1 releases and the accelerating cadence into Q2 require an architectural response.
The wrong response: Select a model vendor, build a deep integration, and plan to reassess in 18 months.
The right response: Build an abstraction layer. Use model-agnostic frameworks. Implement automated evaluation pipelines that can test new model versions against your production workloads on a rolling basis. Structure contracts with AI vendors to include performance improvement provisions rather than locking to specific model versions.
The cost of model-agnostic architecture is a modest upfront engineering investment. The cost of model-specific architecture is rebuilding your AI stack every time a better model emerges — which, in 2026, is every 72 hours.
9. FAQ
What is the most important AI breakthrough of March 2026?
The most commercially significant breakthrough is GPT-5.4’s surpassing of human performance on OSWorld-Verified desktop task benchmarks (75.0% vs the human baseline of 72.4%). This is the first time an AI has demonstrably exceeded average human performance at real computer use — a milestone that expands the range of automatable enterprise workflows to include any task performed through a screen interface, regardless of whether an API exists.
Has AI really surpassed human intelligence in 2026?
No — but it has surpassed human performance on specific, well-defined tasks. GPT-5.4 outperforms humans at navigating desktop interfaces (OSWorld), at graduate-level scientific reasoning (GPQA Diamond), and at a range of professional knowledge work tasks (GDPval). It does not outperform humans on novel physical reasoning, emotional intelligence, genuine creativity, or tasks requiring deep contextual judgment built from lived experience. The benchmarks that AI is now exceeding are the ones measuring defined, measurable performance — not the full breadth of human cognitive capability.
What is a world model and how is it different from a large language model?
A large language model (LLM) learns about the world through text — it builds statistical associations between words and concepts based on written language. A world model learns from sensory data — video, physical sensors, observations of how objects and forces behave — and builds internal representations of how the world actually works, independent of how it is described in language. World models can reason about novel physical situations from first principles; LLMs can only describe situations similar to those they have seen in their training text. Yann LeCun’s AMI Labs is betting that world models represent a more viable path to general AI capability.
Is DeepSeek V4 safe to use in enterprise environments?
DeepSeek V4 can be deployed safely in enterprise environments through self-hosting — downloading the open-weight model and running it on your own infrastructure. In this configuration, no data leaves your environment and there is no dependency on DeepSeek’s servers or any Chinese infrastructure. Enterprises with data sovereignty requirements, regulated data, or national security exposure should always self-host Chinese open-source models rather than using cloud API access. For self-hosted deployments, the data security considerations are equivalent to any other open-source software deployment.
How should businesses respond to the accelerating AI model release pace?
The primary strategic response is architectural: build abstraction layers between your applications and specific AI model versions. Use model-agnostic frameworks and evaluation pipelines that allow you to test and adopt new models without rebuilding your integrations. Avoid long-term contracts that lock you to specific model versions without performance improvement provisions. Treat AI infrastructure the way you treat cloud infrastructure — choose providers for reliability, support, and ecosystem, not for any particular version of a specific product.
When will we see AGI?
The honest answer is that no one knows — and anyone claiming certainty in either direction should be treated with scepticism. What can be said based on March 2026 data: frontier AI models are exceeding human performance on a growing range of specific cognitive benchmarks. The trajectory of improvement is faster than most researchers predicted 24 months ago. The first credible claims of performance matching humans across a comprehensive range of professional knowledge work tasks are likely within 12–18 months. Whether that constitutes “AGI” depends on your definition — and definitions vary enormously across the research community.
What is the cheapest frontier-quality AI model available in March 2026?
DeepSeek V4 is the clear answer on cost-performance grounds. It achieves benchmark performance within 2–5% of GPT-5.4 on most tasks, is free to download and self-host, and — thanks to MODEL1 architecture and sparse FP8 decoding — runs on approximately 40% less GPU memory than equivalent-scale models. For high-volume enterprise workloads where self-hosting is viable, DeepSeek V4 offers the best performance-per-dollar of any available model. GPT-5.4’s 47% token efficiency improvement makes it competitive for API-based deployments, though at a base price of $2.50 per million input tokens it remains substantially more expensive than self-hosted open-source alternatives.
This article was researched and written by the Kersai Research Team. Kersai is a global AI consultancy firm dedicated to helping enterprises confidently navigate the rapidly evolving artificial intelligence landscape — from cutting-edge strategic insights to practical, large-scale AI implementation. To learn more, visit kersai.com.
TAGS: AI News, GPT-5.4, DeepSeek, AI Breakthroughs, World Models, Drug Discovery AI, 2026 AI Update